

DeepSeek公布三大优化技术,线上服务利润率高达545%!
真的没想到,DeepSeek开源周连续五天之后,居然在周六还加更了一期。 中国科技公司的勤劳,你不服不行!Orz 而且,这期的内容更重磅,不仅提到了优化官方在线服务的三大关键技术点,还提到在线服务收益率高达545%的理论值。 这充分说明,出...
 朱 朋博业界动态
朱 朋博业界动态 真的没想到,DeepSeek开源周连续五天之后,居然在周六还加更了一期。 中国科技公司的勤劳,你不服不行!Orz 而且,这期的内容更重磅,不仅提到了优化官方在线服务的三大关键技术点,还提到在线服务收益率高达545%的理论值。 这充分说明,出...
朱 朋博业界动态 
导读 2025年2月24日,DeepSeek宣布正式启动“开源周”活动,旨在通过陆续开源5个代码库,以完全透明的方式与全球开发者社区分享其在人工智能领域的最新研究成果。这一活动标志着DeepSeek在开源战略上的进一步升级,也为全球AI技术...
 李 祥敬智能算力
李 祥敬智能算力 
导读 2025年2月27日,——随着人工智能技术加速渗透金融领域,国产大模型DeepSeek正成为行业数字化转型的核心引擎。从银行业到证券业,从大型机构到中小银行,DeepSeek凭借其开源特性、多模态能力与低成本优势,掀起了一场覆盖全行业...
李 祥敬智能算力 
2月27日,腾讯混元自研的快思考模型Turbo S正式发布。区别于Deepseek R1、混元T1等需要“想一下再回复”的慢思考模型,混元Turbo S能够实现“秒回”,吐字速度提升一倍,首字时延降低44%,同时在知识、数理、创作等方面也有...
 张 妮娜业界动态
张 妮娜业界动态 
近日,亚信科技依托自主研发的渊思·通用人工智能与认知增强平台(TAC MaaS)助力广东联通AI应用全面接入DeepSeek,圆满完成国产NPU算力适配,实现了“国产大模型+算力+大模型服务+垂直场景”的适配闭环,助推广东联通自动化、智能服...
朱 朋博业界动态 
导读 随着科技的飞速进步,人工智能(AI)已悄然渗透到我们生活的方方面面,而医疗领域无疑是其中最为关键且充满潜力的一个。DeepSeek,作为AI技术在医疗领域的杰出代表,正以其独特的方式改变着传统的医疗模式。 本文将深入探讨DeepSee...
李 祥敬智能算力  朱 朋博业界动态
朱 朋博业界动态 
在人工智能技术呈指数级发展的时代浪潮中,深度学习模型作为核心驱动力,正以前所未有的速度重塑着各个领域的发展格局。在这一蓬勃发展的进程里,DeepSeek系列模型凭借其独树一帜的MLA(Multi-Layer Adaptive Archite...
李 祥敬智能算力 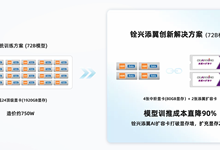
现在越来越有体会:显卡核心性能能决定模型的计算速度,而显卡的显存容量,决定了能处理的数据规模和训练的效率。 特别是最近这几天,在本地部署DeepSeek的时候,很多人会发现,如果显存不够,那么模型根本无法运行。 我在个人台式机上测试后发现,...
朱 朋博智能算力 
导读 就在今天,中国AI领军企业DeepSeek在“开源周”首日祭出“王炸”——FlashMLA代码库正式开源。这一针对英伟达Hopper架构GPU优化的高效多头潜在注意力(MLA)解码内核,上线GitHub仅1小时即狂揽1700颗Star...
李 祥敬智能算力