
龙芯2/Nehalem处理器架构深度对比分析(6)
IT168 发表于:09年06月23日 13:28 [转载] IT168
提交
Commit 提交是流水线的最后一级,在这一级,要把指令们造成的数据变化反映到寄存器/内存上来。和为了顺序提交到寄存器而需要ROB重排序缓冲区的存在一样,在乱序架构中,多个打乱了顺序的Load操作和Store操作也需要按顺序提交到内存,MOB(Memory Reorder Buffer,内存重排序缓冲区)就是起到这样一个作用的重排序缓冲区,ROB和MOB一起形成了一个分布式的Order Buffer结构,有些处理器上只存在ROB,兼备了MOB的功能。
在龙芯2上,ROB和MOB就是架构图上最上方的部分,龙芯2的ROB叫做ROQ(ReOrder Queue,重排序队列),最多可以同时保存32条指令,每时钟周期可以接受4条指令。龙芯2的MOB没有单独的名称,它的容量是16条目。
此外,龙芯2还有一个BRQ(Branch Reorder Queue,分支重排序队列)来管理分支跳转被取消后的重排序。
Cache
缓存
龙芯2具有128KB的L1缓存(Intel方则一直为64KB,AMD的则多为128KB),分为64KB指令和64KB数据,四路集合关联。它们分别 64个条目的数据TLB和16条目的指令TLB。龙芯2支持类似MIPS R5000这样的外部L2缓存,容量从256KB到8KB。
Nehalem/Core 的L1I Cache(L1指令缓存)和L1D Cache(L1数据缓存)都是32KB,不过Nehalem的L1I Cache从以往的8路集合关联降低到了4路集合关联,L1 DTLB也从以往的256条目降低到64条目(64个小页面TLB,32个大页面TLB),并且L1 DTLB是在两个多线程之间动态共享的(L1 ITLB的小页面部分则是静态分区,也就是64条目每线程,是Core 2每线程128条目的一半;每个线程还具有7个大页面L1I TLB)。Nehalem还具有256KB的独享L2 Cache和最多达8MB的共享L3 Cache。
Memory
内存
龙芯2是一个64位MIPS兼容处理器,不过64位的内存寻址几乎很少用到,因此龙芯2实现了40位虚拟寻址和36位物理寻址,36位物理寻址就和x86的PAE模式一样,最大内存支持是64GB,不算高,不过够用了。龙芯2F实现了集成DDR2内存控制器。
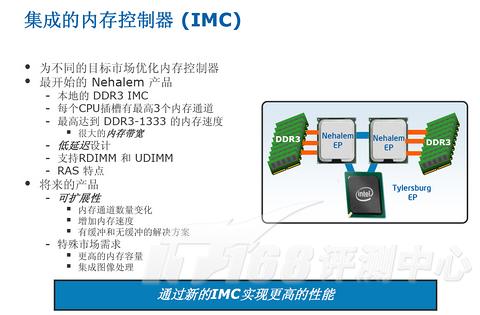
Nehalem:集成内存控制器
Nehalem实现了三通道DDR3 1333集成内存控制器,必须说,这部分包括在架构上的东西是明显影响的存在,虽然x86更渴求内存带宽,不过内存存取无论对哪些架构来说都是至关重要的,这部分上龙芯2还有一大段路要走。
IT168 评测中心:从微架构和架构来看,龙芯2是可圈可点。龙芯2是一个64位、4发射的乱序执行的MIPS兼容RISC处理器,采用了90nm制作工艺(龙芯 2F型。更早期型号使用了0.18um/0.13um工艺),晶体管数量达到了5100万个(集成北桥),功耗很低,1GHz时在5W左右。

作为一款通用处理器,有足够的出货量才能形成一个良性循环(半导体与半倒体:有量才能生存的世界),从这点来看,广泛的应用是必须的。龙芯2就缺乏应用性,而桎梏龙芯广泛应用的最大问题就是软件问题(软件:生态环境的重要性)。就上网本和笔记本市场而言,龙芯2前景不算广大(Linux系统),它应该将目标放在如路由器这样的嵌入式市场上,或者,一些低功耗服务器。据说未来的龙芯3可以支持x86虚拟化,假如实现的话,将可以应用Windows系统,如此其应用程度应该会有较大的提升。




