
龙芯2/Nehalem处理器架构深度对比分析(3)
IT168 发表于:09年06月23日 13:28 [转载] IT168
解码
解码是很有意思的一项设计,通常是类RISC(精简指令集或简单指令集)处理器才有的一项设计,从 Pentium Pro开始在IA架构出现。RISC架构的特点就是指令长度相等,执行时间恒定(通常为一个时钟周期),因此处理器设计起来就很简单,可以通过深长的流水线达到很高的频率(例如 31级流水线的Pentium 4......当然Pentium 4要超过5GHz的屏障需要付出巨大的功耗代价),IBM的Power6就可以轻松地达到4.7GHz的起步频率。关于Power6的架构的非常简单的介绍可以看《机密揭露:Intel超线程技术有多少种?》。和RISC相反,CISC指令的长度不固定,执行时间也不固定,这样设计的流水线效率就不会高,因此Intel就实现了一个RISC/CISC混合处理器架构:通过解码器将x86指令翻译为类似RISC的指令,按照RISC的方式设计和运行,从而获得RISC架构的长处,提升内部执行效率。
通常的RISC指令由于架构简单,因此都是直接运行而不需要进行解码,然而龙芯2不同:它具备一个解码阶段将MIPS指令翻译为龙芯2的内部指令(后面用微指令来指代),这一点看起来和现在的CISC处理器很相似。Intel的内部指令称为 Micro Operation--micro-op,或者写为μ-op,一般用比较方便的写法来替代掉希腊字母:u-op或者uop。相对地,一条一条的x86指令 Intel就称之为Macro Operation,或macro-op。
类似地,AMD的处理器也通过解码器将x86指令翻译为自己的内部指令,并且和Intel的不相同。内部指令集的选取和微架构息息相关,如何实现足见体现出设计团队的功力。内部指令的存在也让不停增加新的指令更为方面,只需要更新解码器的解码表即可。然而,解码器的存在无疑增加了新的流水级,并且很容易成为瓶颈--x86架构上解码器一直都是瓶颈,因为复杂的x86指令可以解码出非常多的微指令来(当然,将以前无解码器时的微架构设计上的困难集中转移到解码器上确实是一个进步)。
Nehalem的解码器也是4个:3个简单解码器加1个复杂解码器,AMD K8则具有三个复杂解码器,龙芯2的数量看起来是四个。为了简化分支管理,每一个时钟周期内只可以解码一条分支指令,整数乘/除指令会被解码成两条微指令。解码是龙芯流水线的第3级。
对于Nehalem的解码器而言,简单解码器可以将一条x86指令(包括大部分SSE指令在内)翻译为一条uop,而复杂解码器则将一些特别的(单条)x86指令翻译为1~4条uops--在极少数的情况下,某些指令需要通过额外的可编程 microcode解码器解码为更多的uops(有些时候甚至可以达到几百个,因为一些IA指令很复杂,并且可以带有很多的前缀/修改量,当然这种情况很少见),下图Complex Decoder左方的ucode方块就是这个解码器,这个解码器可以通过一些途径进行升级或者扩展,实际上就是通过主板Firmware里面的 Microcode ROM部分。
2006年进行的一个研究当中表示,最常用的20条x86指令当中:
mov占35%(寄存器之间、寄存器与内存之间移动数据),push占10%(压入堆栈,也经常用来传递参数),call占6%,cmp占5%,add、pop、lea占4%(实际计算指令非常少)
75%的x86指令短于4 bytes,也就是小于32 bits。不过这些短指令只占代码大小的53%--有一些指令非常长
Nehalem: Decode
在解码器上,Nehalem做了不少优化,如将多条Macro Ops(就是x86指令)聚合的Macro Fusion和将多条uops聚合的Micro Fusion功能,总的来说是用于降低uop的数量。此外,在各种Fusion之后,Nehalem还会做循环检测,剩下相关指令的、取指、分支预测和解码工作。
Register Rename
寄存器重命名
OOOE--Out-of-Order Execution乱序执行是现代超标量处理器的常用设计(和其相对的是IOE--In-Order Execution顺序执行,典型的如如Pentium和Atom处理器),它有些类似于多线程的概念,这些在《机密揭露:Intel超线程技术有多少种?》里面可以看到相关的介绍。乱序执行是为了直接提升ILP(Instruction Level Parallelism)指令级并行化的设计,在多个执行单元的超标量设计当中,一系列的执行单元可以同时运行一些没有数据关联性的若干指令,只有需要等待其他指令运算结果的数据会按照顺序执行,从而总体提升了运行效率。乱序执行引擎是一个很重要的部分,需要进行复杂的调度管理。
首先,在乱序执行架构中,不同的指令可能都会需要用到相同的通用寄存器(GPR,General Purpose Registers),特别是在指令需要改写该通用寄存器的情况下--为了让这些指令们能并行工作,处理器需要准备解决方法。常见的就是引入重命名寄存器(Rename Register),不同的指令可以通过具有名字相同但实际不同的寄存器来解决,相应地加入流水线的一级就叫做Register Rename,或者Register Renaming。在龙芯2上,这是流水线的第4级。
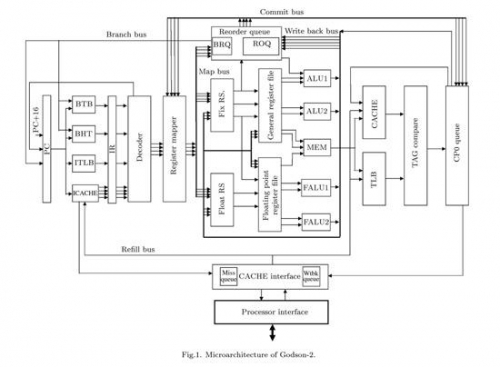
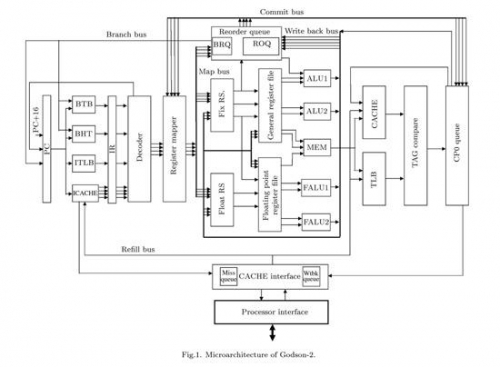
Godson-2 Microarchitecture
通常,寄存器重命名有两种实现方式:虚拟寄存器(称为Architectural Register或Logical Register)与重名名寄存器独立,或者混合,龙芯2和Nehalem都采用了第二种,它们将虚拟寄存器和重命名寄存器混合在一起,使用一个独立的表来建立重命名寄存器与物理寄存器之间的联系,Nehalem的这个表叫做RAT(Register Alias Table,寄存器别名表),龙芯2的这个表叫做PRMT(Physical Register-Mapping Table,物理寄存器映射表),两个平台上都包含了两个这样的表,不过,用途却不相同,Nehalem的两个表是为了超线程的两个线程而准备,而龙芯2的两个表则是分别用于整数和浮点--它们是分开处理的。
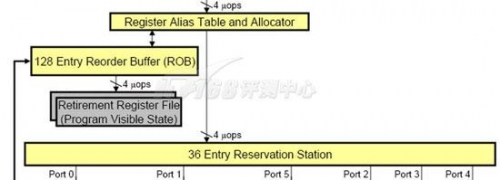
Nehalem: Register Rename(RAT, ROB, RRF)
物理寄存器文件存放的位置也不太一样,Nehalem将其放在ROB附近,龙芯则将其放在Reservation Station(保留站)和执行单元之间。Nehalem的每份RAT包含了128个重命名寄存器,而龙芯2的整数PRMT+浮点PRMT合起来也是 128个条目。
Dispatch
分发
在经过寄存器重命名之后,指令们将会被分发到ROB(在龙芯上,对应的部件叫做ROQ--ReOrder Queue),同时发送到保留站,这个阶段叫做Dispatch分发,在龙芯2上是第5流水线级。和Nehalem不同,龙芯2的Dispatch需要按照指令的种类选择发送到整数还是浮点的保留站,而Nehalem具有一个统一的保留站。
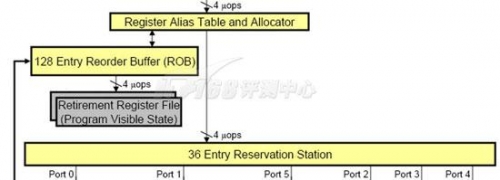
Nehalem: Unified Reservation Station
ROB(Re- Order Buffer,重排序缓冲区)是一个非常重要的部件,它是将乱序执行完毕的指令们按照程序编程的原始顺序重新排序的一个队列,以保证所有的指令都能够逻辑上实现正确的因果关系。打乱了次序的指令们依次插入这个队列,当一条指令通过RAT发往下一个阶段确实执行的时候这条指令(包括寄存器状态在内)将被加入 ROB队列的一端,执行完毕的指令(包括寄存器状态)将从ROB队列的另一端移除(期间这些指令的数据可以被一些中间计算结果刷新),因为调度器是In- Order顺序的,这个队列也就是顺序的。从ROB中移出一条指令就意味着指令执行完毕了,这个阶段叫做Retire回退,相应地ROB往往也叫做 Retirement Unit(回退单元),并将其画为流水线的最后一部分。
在一些超标量设计中,Retire阶段会将ROB的数据写入L1D缓存,而在另一些设计里,写入L1D缓存由另外的队列完成。例如,Core/Nehalem的这个操作就由MOB(Memory Order Buffer,内存重排序缓冲区)来完成。
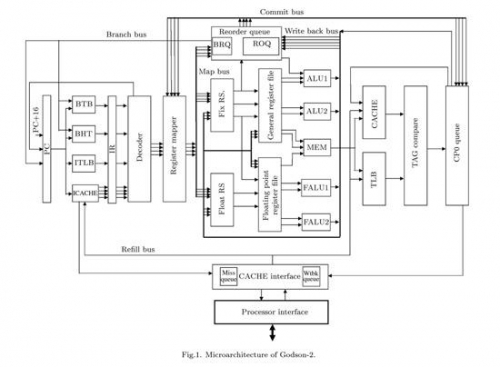
Godson-2 Microarchitecture
RS(Reservation Station,中继站,Intel文档翻译为保留站)上保存了所有等待执行的指令,Nehalem具有36条目的统一保留站,龙芯2则具有16条目的整数和16条目的浮点保留站,从管理上看,统一的保留站更为复杂些,不过灵活性要更好。
除了存放指令之外,保留站的作用是监听内部结果总线上是否有保留站内指令所需要的参数果。需要读取L1/L2缓存乃至内存的指令或者需要等待其他指令结果的指令必须在此等待。




