
HPC China 2012:异构计算GPU的优化处理
咸师 发表于:12年10月31日 10:38 [原创] DOIT.com.cn
2012年10月29日-31日,由中国计算机学会主办的 “2012年全国高性能计算学术年会”(HPC China 2012)在湖南省张家界阳光酒店召开。本届盛会围绕着高性能计算技术的研究进展与发展趋势、高性能计算的重大应用等主题展开,促进信息化与工业化的深度 融合,为相关领域的学者提供交流合作、发布最前沿科研成果的平台,推动中国高性能计算的发展。

2012全国高性能计算大会第三天来自中国科学院计算技术研究所副研究员谭光明发表了关于“面向GPU的快速稠密矩阵乘算法设计和实现”的演讲。谭光明研究员讲解了关于GPU如何优化,提高GPU处理的性能。

【图】中国科学院计算技术研究所副研究员谭光明
目前高性能计算面临着一些问题,首先高性能计算是以低功耗、低占地实现Petaflops计算跨越为目标的,但是要想做到这些,并不是那么容易,在目前几个主流的GPU厂商比如NIVIDA和AMD在GPU工作的效率上都不是很高,像在CUDA DGEMM的NVIDIA Fermi上的效率低于50%在ACML DGEMM的AMD Cypress上的效率低于50%。
目前GPU—CPU都面临一个存储强的问题,主要是带宽和延迟。造成这一问题的主要原因是GPU的矩阵乘算法上。
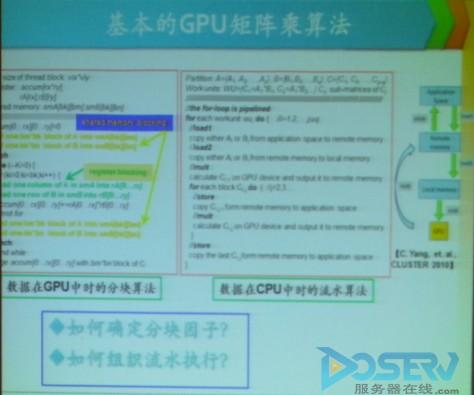
【图】基本GPU矩阵乘算法
在看到GPU矩阵乘算法的问题之后,我们考虑使用更宽的访存指令来提升浮点理论效率,但这个方法也有一个潜在的问题,就是更宽的访存储指令增加了指令流水的延迟。延迟增加了,如何降低延迟呢?谭光明研究员表示,采用数据渗透优化技术,分离计算和访存操作,共享存储中的双缓冲机制。
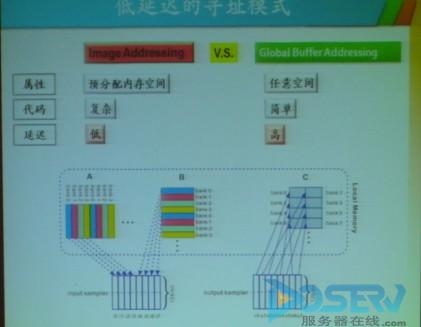
【图】低延迟寻址模式
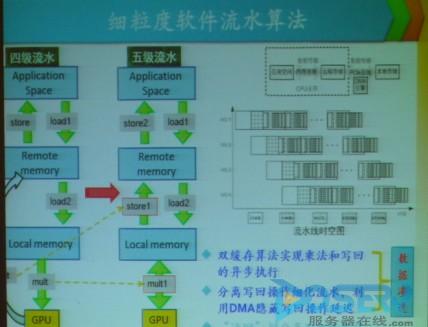
【图】细粒度软件流水算法
通过这种方法优化之后GPU的性能得到了明显的提升
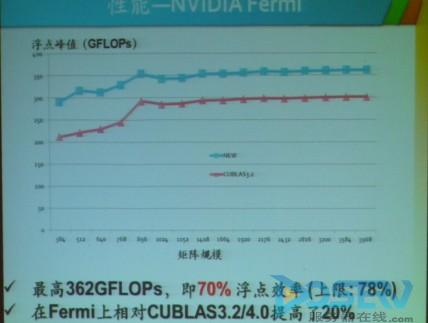
【图】NVIDIA Fermi性能得到提升
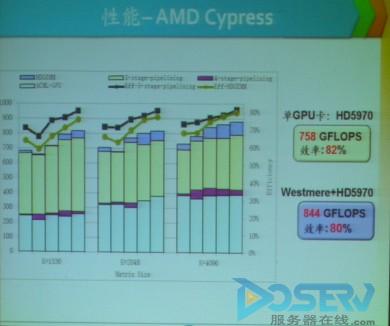
【图】AMD Cypress性能对比
在改善了GPU性能之后,接踵而来的问题就是在多个GPU存在的时候如何保证正常的运算和性能的保持。谭光明研究员表示,在多个GPU存在的时候影响性能的有两方面第一个就是PCIe 的总线影响另一个是CPU内存的影响。
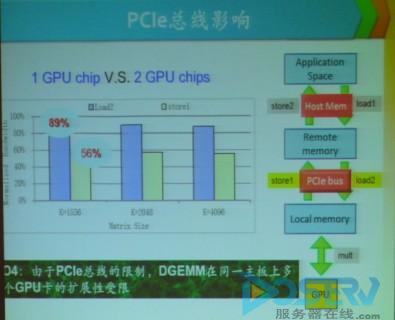
【图】PCIe 总线影响
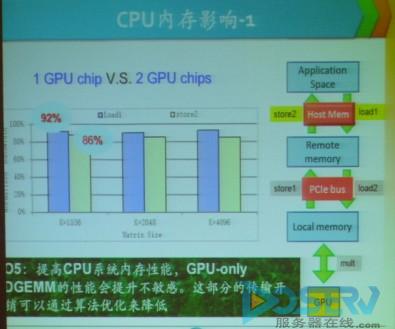
【图】CPU内存影响
那么优化性能的微体系结构因素,主要是基于128-bits访存储指令的新算法提高计算指令的比例,第二新的双缓冲算法,指令调度算法减少长延迟。第三基于量化分析提出改善新体系结构。




