


当前云计算服务发展迅速,超大规模、超高性能、灵活与高可扩展成为云计算业务模式的特征和基本要求,传统技术基础的交换机和路由器的交换架构已不能适用这种大规模、高密集的IT集散模式,而面向统一交换架构和业务融合、更大容量和带宽、更高性能和扩展性、更精细的QoS保证、更高的可靠性和容错性能、智能化和易于管理、绿色节能等技术方向的全新基础网络交换架构,才能满足不断涌现的各种新型业务和应用、改进用户体验,并持续降低单位带宽成本。网络技术架构的进步反过来进一步推进云计算的普及和良性发展。
毫不夸张地说,交换架构是网络设备的核心,就像人的心脏一样重要。交换架构决定了一台设备的容量、性能、扩展性以及QoS等诸多关键属性。在其短短二十几年的历史中,先后出现了共享总线交换、共享存储交换、Crossbar矩阵交换和基于动态路由的CLOS交换架构等不同形态。对于代表业界发展水平的大容量或超大容量的机架式网络设备而言,通常采用Crossbar矩阵交换或CLOS交换架构,共享缓存交换则应用于其线卡作为全分布式业务处理和转发的组成部件。
一、数据中心对新一代交换架构的要求
交换架构的一般模型如图1所示,在逻辑上由数据通道资源、控制通道资源这两个相辅相成的部分构成。数据通道资源具体包括交换网及其端口带宽、交换网适配器(FA:Fabric Adaptor)、流量管理器(TM:Traffic Manager)、缓存(Buffering)以及用于互联的高速总线。控制通道资源则包括用于资源分配、业务调度、拥塞管理的流控单元、调度器(Scheduler),调度器有时也叫仲裁器(Arbiter)。完整意义上的交换架构还包括报文处理器(PP:Packet Processor)或网络处理器(NP:Network Processor)。
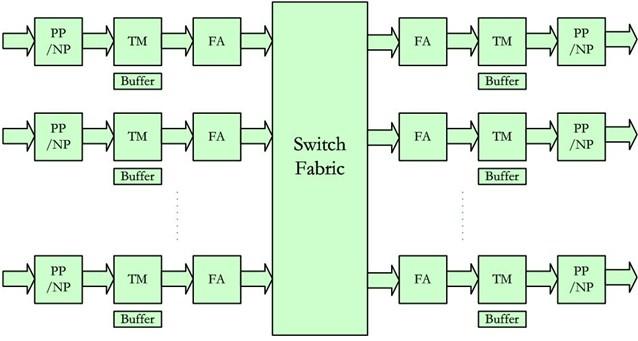
图1 交换架构一般模型
数据中心作为面向应用的综合业务平台和未来云计算的核心基础架构,对网络设备的交换架构提出了更全面、更苛刻的要求,主要包括:支持统一交换架构,大容量及高扩展性,转发性能,业务调度和精细化QoS,弹性。
1、 支持统一交换架构(Unified Switch Fabric)
数据中心目前存在相对独立的三张网:数据网(Data)、存储网(SAN)和高性能计算网(HPC)。为了便于未来的业务整合和服务提供、简化管理、降低建设成本和运营维护成本,三网将逐步走向融合。要求网络设备的交换架构能方便地扩展和支持FCoE、FC等接口及其转发,从而与存储网络无缝融合;支持CEE(Convergence Enhanced Ethernet)增强型以太网等新型接口,使以太网从传统的“尽力而为(Best-effort)”变成更为成熟的“无损网络(Lossless)”。
2、 大容量及高扩展性(Capacity & Scalability)
超宽带时代正在来临,以Youtube、iTunes、Facebook、GoogleEarth、网真系统、移动视频等为代表的视频流、音频流、社交网络、P2P、多媒体等业务正以约70%的年增长速度发展,对未来网络提出了近乎无止境的带宽需求。要求交换机具有大容量和优异的可扩展性,即随着业务拓展而逐步扩展端口数、端口速率,从而提高端口容量。扩展性还包括能根据业务需要扩展新的端口类型,支持网络资源虚拟化,支持集群系统等。
作为衡量系统交换能力和未来可扩展能力关键指标,交换机的交换容量相当于汽车的排量指标。新一代机架式数据中心交换机交换容量在1~10Tbps级别,集群系统更高达几十Tbps。端口容量则指产品当前版本所能提供的最大网络端口容量,由网络端口速率乘以相应的线速端口数得出,表征了产品当前实际所能支持的线速转发能力。同样交换容量的产品,在不同版本和阶段,可能有不同的端口容量;同样交换容量的产品,由于交换架构总开销不同,所能支持的端口容量也会不同。
端口速率:新一代架构要求除支持千兆、万兆以太网端口之外,还要求每槽位能平滑支持一到多个40Gbps和100Gbps端口,这是带宽发展过程中一个质的飞跃。
3、 转发性能
线速转发性能:通常是指64字节小包的线速转发能力,表征了系统处理报文头的能力,在相同的端口流量下,64字节小包要求系统在单位时间内处理更多的报文数。转发性能还要关注线速一致性,即大包小包都能线速,都不丢包;Pair模式、Full Mesh模式都能线速转发。
转发时延及时延抖动:目前存储转发技术的端口到端口时延在几微秒到几十微秒,可满足绝大多数应用场合。Cut-through转发时延可达到1微秒以下,主要用于少数对时延非常敏感的紧耦合高性能计算。时延抖动则指时延的一致性、时延可预测性,VoIP、视频等实时业务通常要求低时延和时延一致性。
4、 业务调度和精细化QoS
近年来带宽需求的年增长达到50~70%,而带宽供给年增长通常在30%。资源总是有限的,不可能给所有用户、所有业务提供足够的带宽,从而导致实际的网络是一个存在拥塞的网络。网络设备需要提供更完善和精细的QoS支持,即根据不同用户不同业务的SLA要求,提供相应有保证或可预测的带宽、丢包率、突发缓存能力、时延、时延抖动等指标承诺。
业务调度和队列(Scheduling & Queuing):没有业务调度的交换架构就像没有红绿灯的十字路口,容易发生碰撞和事故,谈不上QoS。粗放式调度就像每个方向有一个车道,有单一圆形红绿灯的十字路口,比没有红绿灯有大幅改善,但容易阻塞。而精细化调度则好比每个方向有三个车道(左转、直行、右转),红绿灯由三个对应的方向指示箭头组成(左转、直行、右转箭头),这种调度显然效率更高、更加有序了。
在交换机里,车道就好比队列,红绿灯就好比调度器。队列越多,就可以对流量进行更精细化的管理和调度,使到不同出口、不同优先级的业务转发互不影响,消除头阻塞。队列越多,调度器也越复杂,设计复杂度也高,有的设备还支持层次化调度(H-QoS)。所能支持队列数目也是网络设备的关键指标之一,一般设备支持十几、几十到几百条队列不等,少数高端产品可以支持1K、十几K或几十K。
流分类和缓存(Classification & Buffering):与业务调度紧密相关的就是流分类和缓存。流分类是对不同用户和业务进行识别然后映射到不同的优先级和队列。而没有缓存或缓存太小,再好的调度也形同虚设或大打折扣。随着应用越来越复杂,流量突发越来越大,越来越频繁(比如搜索业务),足够大的缓存对新一代数据中心至关重要。
5、 交换架构的弹性(Resiliency)
弹性是指部件出现故障、或人为操作失误时,能够自动检测到,并对故障进行隔离,从而让系统功能性能不受损失或尽可能少受损失(Graceful Degradation)。包括冗余性(Redundancy)和容错性(Fault Tolerance)。采用与主控板物理上独立的N+1交换网板,即转发平面和控制平面物理上分离有利于进一步提高系统的弹性。
二、 传统的基于CIOQ的Crossbar交换架构
基于CIOQ的Crossbar交换架构在上世纪90年代出现。如图2所示,该架构包含一到多个并行工作的无缓存Crossbar芯片,每个Crossbar芯片通过交换网端口FP(Fabric Port)连接到所有输入端口对应的FA端口和所有输出端口对应的交FA端口;业务调度通常采用集中仲裁器,连到所有的输入输出FA芯片和Crossbar芯片;出口FA定时或实时地向仲裁器报告出口拥塞情况。一次典型的交换过程包含三个步骤:(1)输入端口发送业务前,入口FA先要向仲裁器请求发送(Request to transmit);(2)仲裁器根据输出端口队列拥塞情况,给入口FA发送允许发送(Request granted);(3)业务通过交换网转发到输出端口。
在入口方向,缓存采用VoQ(Virtual output Queuing:虚拟输出队列)方式给到不同目的输出端口、不同优先级的业务流分配相应的队列,对入口流量进行缓冲。在出口方向,也有一个缓存,用以吸收交换网过来的突发流量。因此称之为CIOQ(Combined Input Output Queuing:组合输入输出队列)。
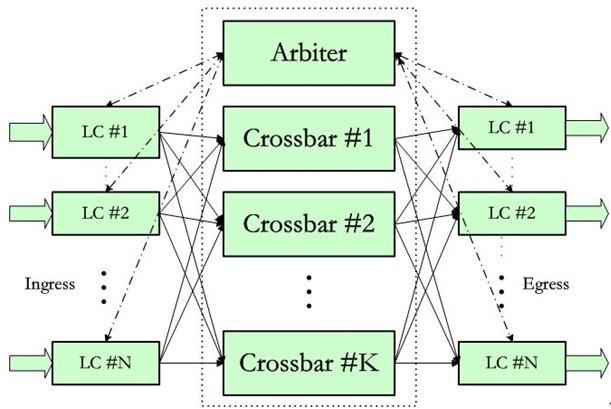
图2 基于CIOQ的Crossbar交换架构
由于是集中调度,所以仲裁器的调度算法复杂度很高,性能扩展性较差,系统容量大时调度器容易形成瓶颈,难以做到精确调度。
由于是粗放型调度,所以在出口方向需要放一个比较大的缓存,并做进一步调度,以支持粒度更细的系统级QoS。为了充分利用出口缓存,需要提高系统加速比,加速比通常达到1.6~2,提高加速比意味着系统能支持的有效端口容量下降(加速比是指交换网端口速率与实际的网络端口速率的比值)。
有些产品交换架构在几何拓扑上将多个Crossbar连成与下文描述的CLOS架构相类似的形式,并采用静态路由方式,即业务流进入交换网前,根据源端口指定或基于Hash算法选择一条路径。所以,属于同一条流的所有报文将选择同一条路径进入交换网。显然,当系统中业务流较为单一时,被Hash算法选中的路径容易形成阻塞,而其它路径则较为空闲。类似道理,业务流从第二级交换到第三级时,也容易形成阻塞。这种架构不是严格意义上的无阻塞CLOS交换架构,其交换性能与基于CIOQ的Crossbar相当。
基于CIOQ的Crossbar同时满足了较大容量交换和较好的业务调度的需求,是一种比较完善的交换架构,交换容量可以从几百G到几T,通常支持10G接口但无法支持40G和100G接口。由于交换容量不是很大,交换网通常集成在主控板上,采用1+1主备或负荷分担工作方式。目前市场上基于10G平台的机架式高端交换机设备通常采用该架构,典型的比如H3C S9500,Cisco C6500。
三、 新一代基于动态路由的CLOS交换架构
CLOS交换架构由贝尔实验室Charles Clos博士在1953年的《无阻塞交换网络研究》论文中首次提出,后被广泛应用于TDM网络,为纪念这一重大成果,便以他的名字CLOS命名这一架构。近二十年来包交换网络的高速发展,迫切需要超大容量和具备优异可扩展性的交换架构,CLOS这个古老而新颖的技术再一次焕发出旺盛的生命力。
CLOS交换架构是一个多级架构;在每一级,每个交换单元都和下一级的所有交换单元相连接。一个典型的CLOS交换三级架构由(k,n)两个参数定义,如图3所示,参数k是中间级交换单元的数量,n表示的是第一级(第三级)交换单元的数量。第一级和第三级由n个k×k的交换单元组成,中间级由k个n×n的交换单元组成。整个构成了k×n的交换网络,即该网络有k×n个输入和输出端口。
对于需要更高容量的交换网,中间级也可以是一个3级的CLOS网络(即CLOS网络可以递归构建),比如4个第一(三)级n×n芯片加上2个n×n的第二级芯片可构成一个2n×2n的交换网。由于CLOS网络的递归特性,它理论上具有无与伦比的可扩展性,支持交换机端口数量、端口速率、系统容量的平滑扩展。
CLOS交换架构可以做到严格的无阻塞(Non-blocking)、可重构(Re-arrangeable)、可扩展(Scalable)。
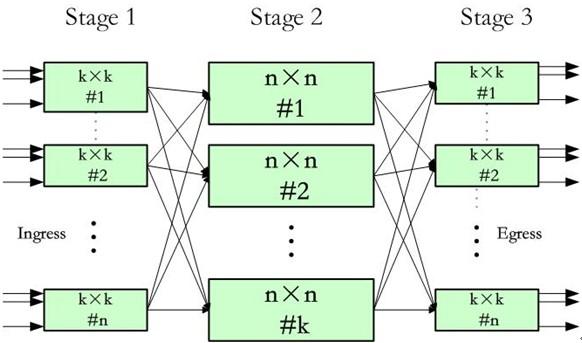
图3 CLOS交换架构
CLOS架构定义了一种几何拓扑结构,在早期TDM及语音应用中,其可重构特性通常由软件计算和配置完成。对于高速包交换系统,大量业务流的目的端口在频繁而快速地变化(如ns级),通过软件来对转发路径进行选择和重配置变得不现实。因此,需要采用近些年专门针对用于包交换系统的CLOS架构而设计的动态路由方式。
动态路由关键点在于能负荷分担地均衡利用所有可达路径。对于第一级,每个业务流可通过Round-robin或随机方式均匀发送到k条连到第二级的路径上(通常基于信元的发送);到达第二级的业务流将基于信元自路由技术(Cell-based Self-routing),根据交换网路由选择相应路径交换到第三级目的端口。第三级收到所有来自第二级的信元时,把信元重组成报文,并保证报文顺序正确。动态路由方式由此实现了严格的无阻塞交换,并有利于减小加速比从而提高有效端口容量。
动态路由方式有一个突出优点,即平滑支持更高速率的网络端口,比如40GE/100GE。这是因为它可以充分利用所有可用路径形成一个大的数据流通道,比如24条3.125Gbps通道可以支持100GE数据流。相反,静态路由方式则受限于单条路径的带宽,比如基于XAUI接口的Crossbar交换,网络端口速率最高只能达到10Gbps,无法支持40GE和100GE。
基于动态路由的CLOS架构,再结合合适的业务调度机制,就可以支持完善的QoS。采用CLOS交换架构的典型设备有:H3C S12500统一交换架构核心交换机,Juniper T1600核心路由器。在2009年2月初,Juniper刚刚发布了TX-Matrix Plus,通过多框互联技术支持把16台T1600构建成一个25Tbps的无阻塞交换系统,显示了CLOS架构卓越的可扩展性。2004年,Cisco发布了其路由器旗舰产品CRS-1,采用了三级动态自路由的Benes交换架构,支持72个机架的互联,达到46T/92T的系统容量。Benes交换实质上是CLOS交换架构的一个特例。
由于CLOS交换系统容量很大,物理实现上,通常采用N+1个独立的交换网槽位,与主控板控制平面彻底分离,一方面提高了系统容量可扩展性,另一方面极大程度上提高了转发平面的可靠性,避免了控制平面出现故障或进行倒换时对转发平面的影响。
六、结束语
对于高端机架式交换机和路由器,以基于CIOQ的Crossbar交换架构和CLOS交换架构为主。其中基于动态路由的CLOS交换架构结合信元自路由技术、分布式调度技术是目前面向新一代数据中心和云计算等多业务复杂应用、适用于大容量核心交换机和核心路由器的最先进、最完善、最理想的一种交换架构。
未经允许不得转载:DOIT » 100G之云内交换篇:面向数据中心的统一交换架构
 英特尔与Submer共推数据中心冷却技术发展
英特尔与Submer共推数据中心冷却技术发展