


城域IP骨干网的变化对新一代核心路由器提出更高要求,H3C CR16000基于100G硬件平台,采用先进的CLOS多级矩阵交换架构,提供持续的带宽升级能力,可以支持40G POS、40GE、100GE和高密10G接口,后续通过递归扩展交换框支持集群技术。本文通过对CR16000转发架构的深入剖析,说明架构改变给设备性能带来的提升。
一、 CLOS交换架构
数据在路由器内部跨端口、跨单板之间的处理,即是交换。交换架构是路由器设备的核心,决定了一台设备的容量、性能、扩展性以及QoS等诸多关键属性。在历史上先后出现五种交换架构,包括:共享总线交换、环型总线交换、共享内存交换、Crossbar矩阵交换和基于动态路由的CLOS多级交换。
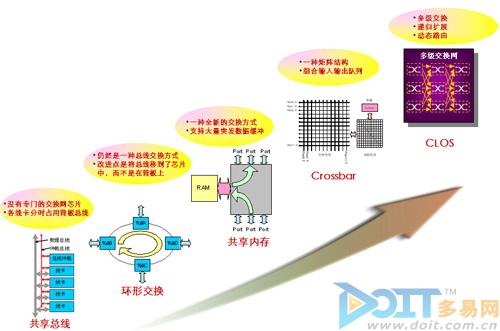
图1 交换架构演进
CLOS交换架构是一个多级架构,在每一级,每个交换单元都和下一级的所有交换单元相连接。一个典型的CLOS交换三级架构由(k,n)两个参数定义,参数k是中间级交换单元的数量,n表示的是第一级(第三级)交换单元的数量。第一级和第三级由n个k×k的交换单元组成,中间级由k个n×n的交换单元组成,整个构成了k×n的交换网络,即该网络有k×n个输入和输出端口。对于需要更高容量的交换网,中间级也可以是一个3级的CLOS网络(即CLOS网络可以递归构建),理论上可以无限可扩展。
CLOS采用动态路由为信元选择交换路径。对于第一级,每个业务流(基于信元)可通过Round-robin方式均匀发送到k条连到第二级的路径上;到达第二级的信元将基于信元自路由技术(Cell-based Self-routing),根据交换网路由选择相应路径交换到第三级目的端口。第三级收到所有来自第二级的信元时,把信元重组成报文,并保证报文顺序正确。这种基于动态路由的信元交换,是完全无阻塞交换。
由于CLOS在交换容量的递归扩展、交换信元的动态选路方面的优势,除了H3C CR16000,其它业界最高端的路由器均采用这种交换架构,例如:Juniper T1600/TX-Matrix Plus、Cisco CRS。
二、 CR16000交换架构
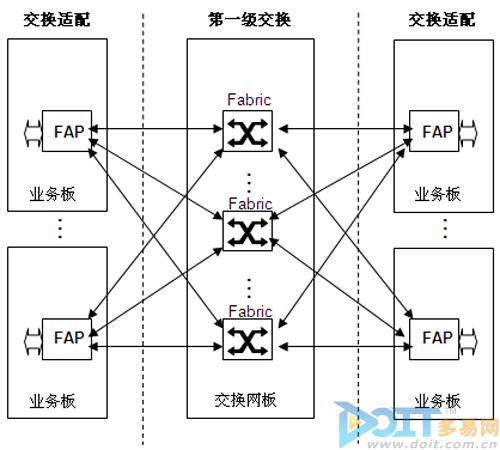
图2 CR16000交换架构
如图2所示,CR16000单框采用的是多级CLOS架构中的第一级交换,由一级交换网Fabric和交换网适配器FAP组成,后续可以通过递归扩展交换网至三级,支持集群功能;CR16000采用独立的网板设计,和主控板物理分离,保证交换和路由完全物理分离,互不影响,提高系统可靠性。一台CR16000有多个交换网板,每个交换网板有1~2个交换网片Fabric,通过多个交换网片Fabric负荷分担支持40G/100G高速端口交换,其主要功能包括:控制信元交换、数据信元交换和路由处理;在每个业务板设计了交换网适配器FAP(Fabric Adapter Processor),FAP在交换网和业务处理芯片(ASIC/NP)之间担当转换器的角色,其主要功能包括:VoQ和Buffer、报文和信元之间的切分和组装、交换调度等。
1. Fabric和FAP之间的连接关系
每个交换网片采用72对SerDes和FAP互连,每个FAP采用18对SerDes和交换网Fabric互连。采用CLOS交换架构为高密度10G端口、40G/100G高速端口提供了充足的交换能力。
下面以CR16018为例来说明CR16000系列路由器的交换网连接关系。

图3 CR16018交换网连接关系
1) CR16018支持9块交换网板,每个交换网板部署2个交换网片Fabric;
2) 支持18个业务槽位,每个槽位有4个交换网适配器FAP,整系统共有72个交换网适配器FAP;
3) 每个交换网片Fabric和每个交换网适配器FAP采用一对SerDes线互连。
4) 如图3所示,每个交换网片采用72对SerDes和FAP互连,每个FAP采用18对SerDes和交换网Fabric互连。
每个业务槽位的交换容量:每个业务槽位有4个FAP,每个FAP有18对SerDes和18块交换网片互连,按照8B/10B编码,交换容量为4×18×2×6.25×0.8=720G bps。
每个网片的交换容量:每个网片有72对SerDes和业务板的FAP互连,SerDes带宽6.25Gbps,按照8B/10B编码,72×2×6.25×0.8 = 720G。
每个网板的交换容量:每个网板含有2个网片,交换容量为720×2=1.44T。
CR16018系统交换容量:1.44T×9 = 12.96Tbps。
由此可知,CR16000采用CLOS交换架构为高密10G端口、40G/100G高速端口提供了充足的交换能力。
2. 交换网Fabric
由于FAP和Fabric之间的交换路径是通过可达控制信元自动学习的,并且交换网交换的是定长信元,我们这种交换体系为“基于信元的动态路由交换”。基于信元的动态路由交换实现了严格的无阻塞交换,充分利用所有可达路径负荷分担形成一个大的数据流通道,平滑支持高速率网络端口。

图4 交换网Fabric
如图4所示,CR16000的交换网片Fabric是一个96×96的交换矩阵,包括Control Cells Switch、Data Cells Switch和Routing Processor,分别对应控制信元交换、数据信元交换和路由处理三个主要部分。
CR16000的交换网是基于信元交换的,由源端FAP将分组报文映射成为40字节的定长信元,然后在Fabric交换网上传送,目的FAP再把这些信元组装成原来的分组报文。采用小的定长信元交换有其内在的优点,信元小意味着通过交换网到达目的节点时间间隔特别短,转发延迟小,相比长帧的转发时延减小30至100倍,能够构成高性能、多节点组成的交换网络。
CR16000交换网的信元可分为控制信元、数据信元两种。
控制信元包括发送队列状态信息(Flow-status)信元、发送报文出队列许可(Credit)信元和可达控制(Reachability control)信元,这些信元是有FAP和Fabric自身产生的。其中,发送队列状态信息(Flow-status)信元和发送报文出队列许可(Credit)信元是用于交换网单播报文的调度控制,在下文会进一步描述。可达控制(Reachability control)信元是在FAP和Fabric之间相互通告连通状态,形成连通表,信元在FAP和Fabric上按照连通表进行交换。
数据信元是由FAP把业务板上需要交换的报文切分成40字节的定长信元,在FAP和Fabric之间交换。
由于FAP和Fabric之间的交换路径是通过可达控制信元自动学习的,并且交换网交换的是定长信元,我们这种交换体系为“基于信元的动态路由交换”。
基于信元的动态路由交换的关键点在于能利用所有可达路径进行负荷分担。在入方向FAP,信元通过Round-robin方式均匀发送到N条连到Fabric的可达路径上;到达Fabric的信元基于信元自路由技术(Cell-based Self-routing),根据交换网路由选择相应路径交换到出方向FAP;出方向FAP收到所有来自Fabric的信元时,把信元重组成报文,并保证顺序正确。
基于信元的动态路由交换实现了严格的无阻塞交换,充分利用所有可达路径负荷分担形成一个大的数据流通道,平滑支持高速率网络端口,如40GE/100GE。
3. 交换网适配器FAP
从整个系统来看,每个FAP都具备业务调度能力,实际上是一种全分布式业务调度,我们称之为“分布式Credit调度机制”。分布式Credit调度机制的优势包括:调度效率高、业务调度精准、拥塞流量分布式缓存等。
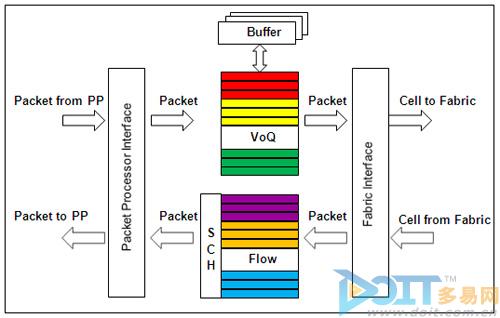
图5 交换网适配器FAP
如图5所示,交换网适配器FAP部署在各个业务板上,在交换网和业务处理芯片PP之间担当转换器的角色,其主要部件包括:VoQ和Buffer、Fabric Inerface和调度器SCH(Scheduler)。
在业务流入方向,FAP从业务处理芯片PP接收到报文,根据目的端口、业务属性以及优先级把业务流映射到不同的VoQ队列当中,实现业务的精细化区分。FAP为整系统的每个出接口都分配了8个VoQ队列,并支持512M buffer用于缓存报文。同时,入方向FAP定时向出方向FAP中的调度器SCH通告VoQ发送队列的属性及空满状态,即发送队列状态信息(Flow-status)信元。
在业务流出方向,调度器SCH根据出端口可用带宽、拥塞情况、对应VoQ的业务属性、优先级和队列空满状态等属性,对所有流向该出口的业务流发送不同带宽许可的Credit。入方向FAP中的每个VoQ队列则根据从调度器SCH收到的Credit给交换网发送相应数量的报文。
每个调度器SCH只负责对流向本出口的业务进行调度,从整个系统来看,每个FAP都具备业务调度能力,实际上是一种全分布式业务调度,我们称之为“分布式Credit调度机制”。
分布式Credit调度机制有很多优势,包括:调度效率高、业务调度精准、拥塞流量分布式缓存等。
– 调度效率高
每个FAP都有一个调度器SCH,并只负责对流向本出口的业务进行调度。以CR16018为例,整机共有72个FAP,即有72个调度器SCH;调度器SCH之间没有主从关系,是完全分布式的并行工作,即CR16018是一个由72个调度器SCH组成的并行工作体系。
– 业务调度精准
Credit调度机制实质是一种令牌调度机制。调度器SCH根据出端口的带宽、拥塞情况等计算出可用带宽,根据入方向FAP通告的发送队列状态信息(Flow-status)并采用整形器(Shaper)算法制定相应的带宽分配策略,最终对每个VoQ生成令牌Credit,VoQ在接收到Credit后发送相应数量的信元。所谓的精准调度包括两个方面的含义:
其一,传统的路由器调度是出接口板缓存和出接口板调度,而CR16000设计的是入接口板缓存和出接口板调度,如果有报文被计算出做丢弃处理,也是在入接口板就被丢弃了,而不会被调度到出接口板做处理,交换网带宽利用精准。
其二,每个调度器SCH对应一个整形器(Shaper),支持双漏桶算法(Dual Leaky Bucket),提供对各业务流及业务流聚合(Aggregate)的流量整形功能(Shaping)。
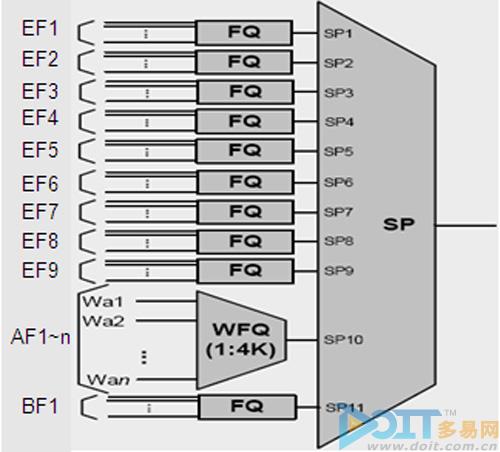
图6 双漏桶算法
入方向VoQ在出方向调度器SCH中对应的是Flow,VoQ和Flow是一一对应关系。调度器SCH把具有相同属性的Flow放入相同的队列,进行FQ/WFQ一级调度,再根据前一级的调度结果进行SP调度,灵活地对各种调度器模块进行组合和编排,以支持个性化的复杂调度策略。此外,还支持针对关键业务的带宽预留功能,支持WRED/Tail Drop拥塞管理策略。
– 拥塞流量分布式缓存
传统路由器的报文在调度发送之前是缓存在出接口板中的,拥塞缓存的能力取决于出接口板的缓存大小。CR16000交换网采用Credit调度机制,报文发送之前,报文缓存在入接口板,调度在出接口板,调度器SCH根据出端口可用带宽和拥塞情况制定相应调度策略,一旦发生拥塞,调度器SCH就不会发送Credit,报文继续被缓存在入接口板。
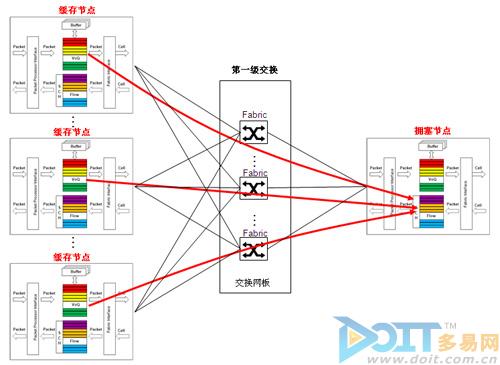
图7 分布式缓存
如图7所示,在N个入接口向1个出接口发生报文的情况下,拥塞流量分布缓存在N个入接口板,报文缓存能力实际上是被放大N倍。随着云业务的应用发展,流量突发越来越大,越来越频繁,如:搜索业务,分布式缓存无疑是当前解决突发拥塞的最佳方案之一。
4. 交换网组播
通过交换网组播技术避免交换网资源的浪费,提升组播业务性能,达到线速复制能力。
传统路由器在组播功能上最重大的缺陷之一就是交换网不支持组播,组播报文在交换网上广播转发,这种处理方式导致的严重后果是组播流量越大,交换网的广播流量就越大,带宽资源浪费就越严重。
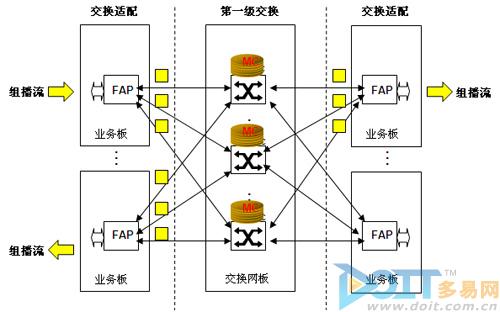
图8 交换网组播
如图8所示,CR16000交换网针对上述问题做了重大的技术改进,即在交换网上增加组播表项存储空间,并同步学习由主控板下发的组播表项。交换网上的组播表项和业务板上的组播表项有一定的区别,业务板上的组播表项为:源IP + 组播IP + 出接口列表,交换网板上的组播表项为:源IP + 组播IP + 出FAP列表,即:交换网板上的组播表项的下一跳为FAP而不是出接口。CR16000交换网组播技术可以避免交换网资源的浪费,提升组播业务性能,达到线速复制能力。
三、 结束语
H3C CR16000采用的CLOS交换架构是业界最优秀的交换架构之一,其特点包括:递归扩展、高交换带宽、无阻塞性、基于信元的动态路由交换、分布式Credit调度机制、拥塞流量分布式缓存、交换网支持组播等,这些特点决定了CR16000的良好扩展性、高可靠性和高性能优势。
未经允许不得转载:DOIT » H3C CR16000大容量转发架构解析

 针对1%户外用户,AGM发布 G1系列旗舰手机
针对1%户外用户,AGM发布 G1系列旗舰手机 2021数据与存储峰会为什么没有超融合论坛了?
2021数据与存储峰会为什么没有超融合论坛了? 让超算再升级的存储系统,华为凭什么?
让超算再升级的存储系统,华为凭什么?