



GPU驱动“后摩尔定律时代” 为HPC和深度学习提供强大加速动力
[导读]2015年11月10日消息:2015年全国高性能计算学术年会(HPC China 2015)上英伟达及应用其GPU的众多企业与科研机构,带来近20场报告和演讲
2015年11月10日消息:2015年全国高性能计算学术年会(HPC China 2015)上英伟达及应用其GPU的众多企业与科研机构,带来近20场报告和演讲,针对GPU的最新技术以及GPU在科学计算、大数据分析、深度学习乃至自动驾驶汽车领域的应用和创新,做了深度解读和分享。随着深度学习爆发式发展,GPU成为HPC 领域受关注的焦点。
NVIDIA解决方案工程架构副总裁Marc Hamilton提到:“在NVIDIA的推动下,过去7年间整个加速计算领域获得了10倍的增长,NVIDIA的GPU加速器占据了加速器市场85%的份额。同时在GPU的驱动下全球和中国都掀起了深度学习热潮,GPU也已成为深度学习研究的首选技术平台。此次大会我们非常高兴地看到GPU帮助了众多企业和研究机构在HPC和深度学习领域实现大量创新应用,相信我们将于明年面世的下一代GPU架构Pascal和NVLink高速互联技术,将为数据中心和深度学习提供更加强大的加速动力。”
“后摩尔定律”时代 GPU提供强大加速动力
计算核心并没有越来越快,只不过处理器正朝着并行化的方向发展。如今我们已步入了“后摩尔定律时代”,处理器单线程性能的增速放缓,逻辑核心数量则在不断增加,由CPU和加速器构成的加速计算体系,成为整个计算领域的必然趋势。
目前,加速器发展势头迅猛,自2010年到今天的短短几年时间,全球超级计算机TOP 500榜单中采用加速器的系统就已经达到90台。同时,最常用的50款HPC应用中有70%已支持加速器加速。
NVIDIA在整个加速计算领域中居于主导地位,其推出的Tesla GPU加速器和CUDA®并行计算架构,在过去7年中引领了加速计算领域10倍以上的增长,例如支持CUDA的应用数量从27款增长至334款,Tesla GPU加速器的使用量从6,000个增加至45万个,占据整个加速器市场85%的份额。
2008年全球首台GPU超级计算机即由Tesla GPU加速器驱动,随后几年内Tesla GPU加速器更成就多台顶级超级计算机,例如美国的泰坦系统。而当前美国基于Tesla GPU加速器正构建两台新一代超级计算机高峰和峰峦,将距离百亿亿次级计算目标更近一步。
NVIDIA的Tesla GPU加速器还在2013年帮助科学家实现重大突破,首次确定了HIV"病毒衣壳"的准确化学结构。而如果不使用GPU,则需要5倍的处理器规模才能达到近似的性能;Tesla GPU加速器还可显著提升成本效益,例如谷歌大脑系统在使用Tesla加速器后,性能提升到之前的6倍,而能耗却从原先的600千瓦降低到4千瓦。
高密度GPU服务器也已成为主流,Cray、DELL、HP以及Quanta都已推出支持Tesla GPU加速器的产品,可为HPC客户提供直接、完整的解决方案。
围绕Tesla GPU加速器和CUDA并行计算架构,NVIDIA推出了Tesla加速计算平台,专门针对大数据分析与科学计算领域的密集型计算需求,构建了一个由软件开发者、软件供应商以及数据中心系统OEM厂商组成的综合生态系统。Tesla平台可为高性能计算专业人士提供所需的工具,使其能够在数据中心轻松地打造、测试和部署加速的应用。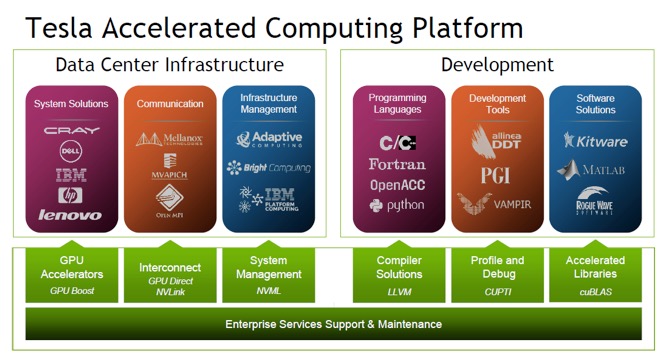 当前Tesla加速计算平台的最新旗舰是Tesla K80双GPU加速器,它可提供最快的数据分析和科学计算性能,被众多对计算有较高要求的企业和研究机构列为首选升级方案。
当前Tesla加速计算平台的最新旗舰是Tesla K80双GPU加速器,它可提供最快的数据分析和科学计算性能,被众多对计算有较高要求的企业和研究机构列为首选升级方案。
Tesla K80拥有带宽极高的24GB内存、高达8.74TFlops的单精度峰值浮点性能和高达2.91 TFlops的双精度峰值浮点性能。在数百款HPC应用中,Tesla K80比当今最快CPU快10倍。
得益于优秀的性能表现,Tesla K80已开始在全球得到广泛应用。瑞士联邦气象气候局利用基于Tesla K80的超级计算机,将气象模型解析度和能源使用效率分别提升到之前的两倍和三倍。同时,Tesla K80也在各项超算大赛中发挥重要优势,帮助清华大学先后在今年ASC和ISC两次超算大赛中获得总冠军。也因此让Tesla GPU加速器公认成为在超算大赛中获得优胜的首选加速方案。
作为能够让开发人员轻松为应用实现GPU加速的并行编程标准,NVIDIA一直推动其在HPC领域中的普及,并促进其在更多的加速器平台和CPU架构上的应用。目前全球已经有超过8,000名研究人员在采用OpenACC。NVIDIA在今年推出的OpenACC工具包可以帮助开发人员快速利用OpenACC实现应用加速;在上月末推出的新增对x86多核CPU的OpenACC支持的新版PGI加速器编译器,让开发者能够对基于OpenACC的源代码进行编译,使其可以在多核CPU或GPU加速器上并行执行,为开发者带来巨大的灵活性。
硬件架构的升级也将进一步推动HPC行业的发展,将随NVIDIA下一代GPU架构Pascal一同到来的NVLink高速互联技术可以为超级计算机内CPU和GPU之间、以及GPU和GPU之间的数据传输带来现有PCI-Express总线5倍的带宽,最终的应用性能也将获得两倍以上性能提升,为数据中心和深度学习提供强大的加速动力。
可以说,GPU加速器彻底改变了高性能计算行业。
GPU掀起深度学习革命 助力全球多领域创新
深度学习如今成为HPC行业中一个爆发式增长的应用方向,大数据、算法的进步、强大的GPU加速,共同驱动了深度学习研究和应用热潮。诸如Adobe、百度、谷歌、Facebook、IBM等企业已成为深度学习领域的探索者和领导者,并在包括图像识别、人脸识别、语音识别、视频分析、语音识别和翻译、自然语言处理等方面促成了大量革命性的进展和创新,这些创新已被广泛应用于社交网络、安防和能源领域。 在医学研究领域,深度学习助力创造多项革命,例如乳腺癌细胞有丝分裂检测、药物发现领域的分子活动预测、预测新型药物的毒性,以及帮助科学家了解基于突变防止疾病。
在医学研究领域,深度学习助力创造多项革命,例如乳腺癌细胞有丝分裂检测、药物发现领域的分子活动预测、预测新型药物的毒性,以及帮助科学家了解基于突变防止疾病。
在图像识别领域,以ImageNet大规模视觉识别挑战赛为例,GPU在2012年被首次应用即取得了突破性成绩,它帮助多伦多大学大幅提升了识别精度,将错误率从之前两年的28%和26%直接降低到了16%,也由此掀起了GPU加速深度学习的热潮。
作为深度学习研究技术平台领导厂商,NVIDIA先后推出了多项创新产品和技术,助力国内外各大企业实现创新应用,NVIDIA GPU也成为深度学习研究首选平台。 在硬件方面,得益于统一的GPU架构,从嵌入式到桌面再到HPC和云服务,NVIDIA可为不同的硬件平台均提供深度学习研究的支持。其中,Tesla K80即有针对深度学习任务的优化,在深度学习框架Caffe中,Tesla K80的速度更可以比CPU快上近24倍。
在硬件方面,得益于统一的GPU架构,从嵌入式到桌面再到HPC和云服务,NVIDIA可为不同的硬件平台均提供深度学习研究的支持。其中,Tesla K80即有针对深度学习任务的优化,在深度学习框架Caffe中,Tesla K80的速度更可以比CPU快上近24倍。
在软件方面,NVIDIA推出了DIGITS深度学习训练系统,它是首个专门用于图像分类的全功能图像系统,可用于设计、训练和验证深度神经网络,目前已推出最新的DIGITS 2可以充分利用多GPU扩展实现性能翻倍。NVIDIA还推出了cuDNN(CUDA深度神经网络库),让开发者可以将其集成到更高级的机器学习框架如Caffe、Torch、Theano中,这些框架均可充分利用GPU加速,帮助研究人员高效地训练更大、更复杂的神经网络。
NVIDIA还联合曙光、浪潮等HPC领域的众多合作伙伴,推动中国深度学习生态链的构建,助力中国企业在深度学习领域的创新。例如此次NVIDIA 展台展示的曙光XSystem深度学习产品,可为用户提供完整的软硬件一体化深度学习解决方案;NVIDIA与曙光、中科院计算技术研究所共建的深度学习与高性能计算联合实验室,将联合开展深度学习软硬件产品的开发和推广工作。
目前,基于NVIDIA GPU的深度学习平台已帮助谷歌、Facebook、阿里巴巴、百度、腾讯、京东、网易、科大讯飞、搜狗、爱奇艺等国内外知名企业实现创新研究和应用。例如,谷歌研究院利用GPU,在自动驾驶、智能交通领域关键技术行人检测方面实现了的性能与精度的双重飞跃;阿里云推出的中国第一个基于GPU计算的HPC云服务为诸多从事深度学习创新企业提供加速支持;百度研发的计算机视觉系统Deep Image和深度语音识别系统Deep Speech均在GPU的加持下实现了识别速度和精度的显著提高。
深度学习还促成了新一轮创业热潮,包括格林深瞳、旷视科技、图普科技、Linkface、轻搜、元趣、小猿搜题等新兴企业依托于NVIDIA GPU已开发出了大量的创新产品。
NVIDIA解决方案工程架构副总裁Marc Hamilton提到:“在NVIDIA的推动下,过去7年间整个加速计算领域获得了10倍的增长,NVIDIA的GPU加速器占据了加速器市场85%的份额。同时在GPU的驱动下全球和中国都掀起了深度学习热潮,GPU也已成为深度学习研究的首选技术平台。此次大会我们非常高兴地看到GPU帮助了众多企业和研究机构在HPC和深度学习领域实现大量创新应用,相信我们将于明年面世的下一代GPU架构Pascal和NVLink高速互联技术,将为数据中心和深度学习提供更加强大的加速动力。”
“后摩尔定律”时代 GPU提供强大加速动力
计算核心并没有越来越快,只不过处理器正朝着并行化的方向发展。如今我们已步入了“后摩尔定律时代”,处理器单线程性能的增速放缓,逻辑核心数量则在不断增加,由CPU和加速器构成的加速计算体系,成为整个计算领域的必然趋势。
目前,加速器发展势头迅猛,自2010年到今天的短短几年时间,全球超级计算机TOP 500榜单中采用加速器的系统就已经达到90台。同时,最常用的50款HPC应用中有70%已支持加速器加速。
NVIDIA在整个加速计算领域中居于主导地位,其推出的Tesla GPU加速器和CUDA®并行计算架构,在过去7年中引领了加速计算领域10倍以上的增长,例如支持CUDA的应用数量从27款增长至334款,Tesla GPU加速器的使用量从6,000个增加至45万个,占据整个加速器市场85%的份额。
2008年全球首台GPU超级计算机即由Tesla GPU加速器驱动,随后几年内Tesla GPU加速器更成就多台顶级超级计算机,例如美国的泰坦系统。而当前美国基于Tesla GPU加速器正构建两台新一代超级计算机高峰和峰峦,将距离百亿亿次级计算目标更近一步。
NVIDIA的Tesla GPU加速器还在2013年帮助科学家实现重大突破,首次确定了HIV"病毒衣壳"的准确化学结构。而如果不使用GPU,则需要5倍的处理器规模才能达到近似的性能;Tesla GPU加速器还可显著提升成本效益,例如谷歌大脑系统在使用Tesla加速器后,性能提升到之前的6倍,而能耗却从原先的600千瓦降低到4千瓦。
高密度GPU服务器也已成为主流,Cray、DELL、HP以及Quanta都已推出支持Tesla GPU加速器的产品,可为HPC客户提供直接、完整的解决方案。
围绕Tesla GPU加速器和CUDA并行计算架构,NVIDIA推出了Tesla加速计算平台,专门针对大数据分析与科学计算领域的密集型计算需求,构建了一个由软件开发者、软件供应商以及数据中心系统OEM厂商组成的综合生态系统。Tesla平台可为高性能计算专业人士提供所需的工具,使其能够在数据中心轻松地打造、测试和部署加速的应用。
Tesla K80拥有带宽极高的24GB内存、高达8.74TFlops的单精度峰值浮点性能和高达2.91 TFlops的双精度峰值浮点性能。在数百款HPC应用中,Tesla K80比当今最快CPU快10倍。
得益于优秀的性能表现,Tesla K80已开始在全球得到广泛应用。瑞士联邦气象气候局利用基于Tesla K80的超级计算机,将气象模型解析度和能源使用效率分别提升到之前的两倍和三倍。同时,Tesla K80也在各项超算大赛中发挥重要优势,帮助清华大学先后在今年ASC和ISC两次超算大赛中获得总冠军。也因此让Tesla GPU加速器公认成为在超算大赛中获得优胜的首选加速方案。
作为能够让开发人员轻松为应用实现GPU加速的并行编程标准,NVIDIA一直推动其在HPC领域中的普及,并促进其在更多的加速器平台和CPU架构上的应用。目前全球已经有超过8,000名研究人员在采用OpenACC。NVIDIA在今年推出的OpenACC工具包可以帮助开发人员快速利用OpenACC实现应用加速;在上月末推出的新增对x86多核CPU的OpenACC支持的新版PGI加速器编译器,让开发者能够对基于OpenACC的源代码进行编译,使其可以在多核CPU或GPU加速器上并行执行,为开发者带来巨大的灵活性。
硬件架构的升级也将进一步推动HPC行业的发展,将随NVIDIA下一代GPU架构Pascal一同到来的NVLink高速互联技术可以为超级计算机内CPU和GPU之间、以及GPU和GPU之间的数据传输带来现有PCI-Express总线5倍的带宽,最终的应用性能也将获得两倍以上性能提升,为数据中心和深度学习提供强大的加速动力。
可以说,GPU加速器彻底改变了高性能计算行业。
GPU掀起深度学习革命 助力全球多领域创新
深度学习如今成为HPC行业中一个爆发式增长的应用方向,大数据、算法的进步、强大的GPU加速,共同驱动了深度学习研究和应用热潮。诸如Adobe、百度、谷歌、Facebook、IBM等企业已成为深度学习领域的探索者和领导者,并在包括图像识别、人脸识别、语音识别、视频分析、语音识别和翻译、自然语言处理等方面促成了大量革命性的进展和创新,这些创新已被广泛应用于社交网络、安防和能源领域。
在图像识别领域,以ImageNet大规模视觉识别挑战赛为例,GPU在2012年被首次应用即取得了突破性成绩,它帮助多伦多大学大幅提升了识别精度,将错误率从之前两年的28%和26%直接降低到了16%,也由此掀起了GPU加速深度学习的热潮。
作为深度学习研究技术平台领导厂商,NVIDIA先后推出了多项创新产品和技术,助力国内外各大企业实现创新应用,NVIDIA GPU也成为深度学习研究首选平台。
在软件方面,NVIDIA推出了DIGITS深度学习训练系统,它是首个专门用于图像分类的全功能图像系统,可用于设计、训练和验证深度神经网络,目前已推出最新的DIGITS 2可以充分利用多GPU扩展实现性能翻倍。NVIDIA还推出了cuDNN(CUDA深度神经网络库),让开发者可以将其集成到更高级的机器学习框架如Caffe、Torch、Theano中,这些框架均可充分利用GPU加速,帮助研究人员高效地训练更大、更复杂的神经网络。
NVIDIA还联合曙光、浪潮等HPC领域的众多合作伙伴,推动中国深度学习生态链的构建,助力中国企业在深度学习领域的创新。例如此次NVIDIA 展台展示的曙光XSystem深度学习产品,可为用户提供完整的软硬件一体化深度学习解决方案;NVIDIA与曙光、中科院计算技术研究所共建的深度学习与高性能计算联合实验室,将联合开展深度学习软硬件产品的开发和推广工作。
目前,基于NVIDIA GPU的深度学习平台已帮助谷歌、Facebook、阿里巴巴、百度、腾讯、京东、网易、科大讯飞、搜狗、爱奇艺等国内外知名企业实现创新研究和应用。例如,谷歌研究院利用GPU,在自动驾驶、智能交通领域关键技术行人检测方面实现了的性能与精度的双重飞跃;阿里云推出的中国第一个基于GPU计算的HPC云服务为诸多从事深度学习创新企业提供加速支持;百度研发的计算机视觉系统Deep Image和深度语音识别系统Deep Speech均在GPU的加持下实现了识别速度和精度的显著提高。
深度学习还促成了新一轮创业热潮,包括格林深瞳、旷视科技、图普科技、Linkface、轻搜、元趣、小猿搜题等新兴企业依托于NVIDIA GPU已开发出了大量的创新产品。

朱朋博
热点文章





微信公众平台:搜索"doitmedia"
或扫描下面的二维码:

